在人工智能领域,视觉语言模型的发展一直是研究者们关注的焦点。近日,阿里巴巴集团旗下的研究团队经过近一年的不懈努力,终于推出了新一代的视觉语言模型——Qwen2-VL。这一模型的问世,不仅在技术上取得了重大突破,更在实际应用中展现了强大的潜力。

一、Qwen2-VL的显著特点
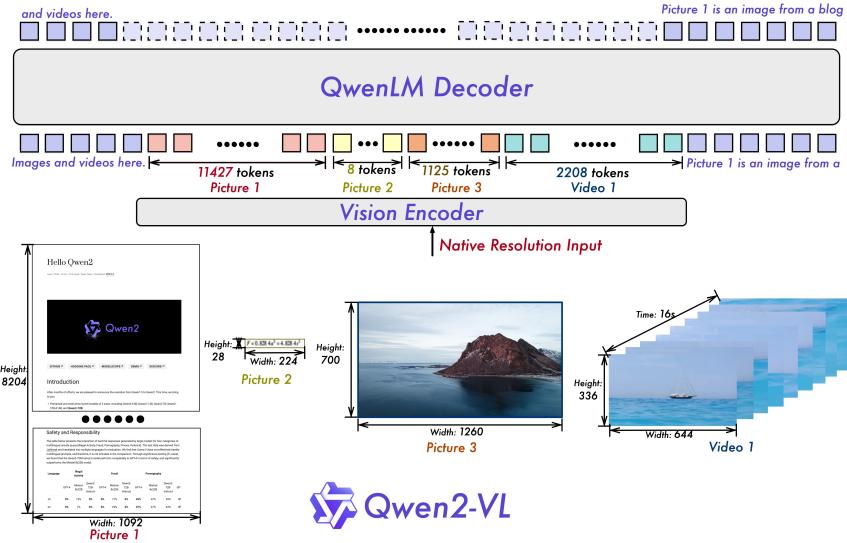
与上一代模型Qwen-VL相比,Qwen2-VL在多个方面都有了显著的提升。首先,它在处理不同分辨率和长宽比的图片方面表现出了强大的能力。在模型性能方面,Qwen2-VL也展现出了强大的实力。从综合大学题目、数学能力、文档表格多语言文字图像的理解、通用场景下的问答、视频理解到Agent能力等六个方面进行评估,Qwen2-VL在大部分指标上都达到了最优水平。特别是在文档理解和多语言文字图像理解方面,它更是展现出了明显的优势。这得益于其深度学习和图像处理技术的完美结合,使得模型能够准确识别并理解图像中的各种细节和信息。

其次,Qwen2-VL在视频理解方面也有着出色的表现。它可以理解长达20分钟以上的视频内容,并将其应用于基于视频的问答、对话和内容创作等多个场景。这一功能的实现,不仅丰富了模型的应用场景,也为用户带来了更加便捷和高效的服务体验。
此外,Qwen2-VL还具备多语言支持能力。除了英语和中文外,它还能够理解包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语在内的多种语言文本。这使得Qwen2-VL在全球范围内都能发挥出巨大的价值,为不同语言背景的用户提供精准的服务。

为了让更多的研究者和开发者能够使用和优化这一模型,阿里巴巴团队以Apache 2.0协议开源了Qwen2-VL-2B和Qwen2-VL-7B两个版本,并提供了Qwen2-VL-72B的API接口。这一举措无疑将推动视觉语言模型的进一步发展和应用。

三、Qwen2-VL的应用场景与创新
除了强大的视觉理解和多语言支持能力外,Qwen2-VL还在多个应用场景中展现出了巨大的潜力。它可以作为手机和机器人的视觉智能体,根据视觉环境和文字指令进行自动操作。这一功能的实现,将为智能设备带来更加智能化和个性化的服务体验。
此外,Qwen2-VL还具备强大的函数调用和视觉交互能力。它可以通过解读视觉线索调用外部工具进行实时数据检索,如航班状态、天气预报等。同时,它还能够与环境进行交互,代替人完成一些执行任务。这些功能的实现,将使得Qwen2-VL在实际应用中发挥出更大的价值。
在架构创新方面,Qwen2-VL实现了对原生动态分辨率的全面支持,并引入了多模态旋转位置嵌入(M-ROPE)技术。这些创新使得模型能够更好地理解和建模复杂的多模态数据,提高了模型的性能和泛化能力。

四、Qwen2-VL的未来展望
尽管Qwen2-VL已经取得了显著的成果,但它仍然存在一些局限性。例如,它目前还无法从视频中提取音频信息,知识库也仅更新至2023年6月。然而,随着技术的不断发展和数据的不断积累,我们有理由相信Qwen2-VL将会在未来取得更加卓越的成绩。
展望未来,Qwen2-VL有望在更多领域发挥出其强大的能力。在智能客服领域,它可以实现更加自然、高效的人机交互体验;在智能家居领域,它可以为用户提供更加个性化、智能化的服务;在自动驾驶领域,它可以提高车辆的感知和决策能力,提升行驶安全性。
总之,阿里巴巴发布的Qwen2-VL无疑为视觉语言模型的发展揭开了新的篇章。它的强大性能和创新应用将为人工智能领域带来更多的可能性和机遇。我们期待在未来看到更多基于Qwen2-VL的创新应用和实践案例涌现出来。
 韦德体育官方网站
韦德体育官方网站
发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。